
上学期期末考试,女朋友C语言怕挂课,我给她整理了一个秘籍,分享一下。
秘籍
ps :好多定义是百度百科的,看不懂一定要问我~
语言基础
什么是 main() ?
可以理解为程序运行时就会执行 main() 中的代码。
最后的 return 0; 表示程序运行成功。默认情况下,程序结束时返回 0 表示一切正常,否则返回值表示错误代码。这个值返回给谁呢?其实就是调用你写的程序的系统或外部程序,它会在你的程序结束时接收到这个返回值。如果不写 return 语句的话,程序正常结束默认返回值也是 0。
数据类型
C 内置了六种基本数据类型:
| 类型 | 关键字 |
|---|---|
| 字符型 | char |
| 整型 | int |
| 浮点型 | float |
| 双浮点型 | double |
| 无类型 | void |
对于 int 关键字,可以使用如下修饰关键字进行修饰:
符号性:
-
signed:表示带符号整数(默认); -
unsigned:表示无符号整数。
大小:
-
short:表示 至少 $16$位整数; -
long:表示 至少 $32$ 位整数; -
long long:表示 至少 $64$ 位整数。
定义变量
简单地说,定义一个变量,需要包含类型说明符(指明变量的类型),以及要定义的变量名。
例如,下面这几条语句都是变量定义语句。
int yz;
double yrh;
char yrh = 's';
变量作用域
作用域是变量可以发挥作用的代码块。
全局变量的作用域,自其定义之处开始,至文件结束位置为止。
局部变量的作用域,自其定义之处开始,至代码块结束位置为止。
由一对大括号括起来的若干语句构成一个代码块。
int g = 20; // 定义全局变量
int main() {
int g = 10; // 定义局部变量
printf("%d\n", g); // 输出 g
return 0;
}
如果一个代码块的内嵌块中定义了相同变量名的变量,则内层块中将无法访问外层块中相同变量名的变量。
例如上面的代码中,输出的$g$的值将是$10$ 。因此为了防止出现意料之外的错误,请尽量避免局部变量与全局变量重名的情况。
常量
常量是固定值,在程序执行期间不会改变。
常量的值在定义后不能被修改。定义时加一个 const 关键字即可。
const int a = 2;
a = 3;
如果修改了常量的值,在编译环节就会报错:error: assignment of read-only variable‘a’。
scanf 与 printf
scanf 与 printf 其实是 C 语言提供的函数。
scanf 为什么会有 &
在这里,& 实际上是取址运算符,返回的是变量在内存中的地址。而 scanf 接收的参数就是变量的地址。具体可能要在 指针 才能完全清楚地说明,现在只需要记下来就好了。
什么是 \n
\n 是一种 转义字符,表示换行。
转义字符用来表示一些无法直接输入的字符,如由于字符串字面量中无法换行而无法直接输入的换行符,由于有特殊含义而无法输入的引号,由于表示转义字符而无法输入的反斜杠。
常用的转义字符有:
-
\t表示制表符。 -
\\表示\。 -
\"表示"。 -
\0表示空字符,用来表示 C 风格字符串的结尾。 -
\r表示回车。Linux 中换行符为\n,Windows 中换行符为\r\n。在 OI 中,如果输出需要换行,使用\n即可。但读入时,如果使用逐字符读入,可能会由于换行符造成一些问题,需要注意。例如,gets将\n作为字符串结尾,这时候如果换行符是\r\n,\r就会留在字符串结尾。 - 特殊地,
%%表示%,只能用在printf或scanf中,在其他字符串字面量中只需要简单使用%就好了。
#include
int main() {
int x, y;
scanf("%d%d", &x, &y); // 读入 x 和 y
printf("%d\n%d", y, x); // 输出 y,换行,再输出 x
return 0;
}
其中,%d 表示读入/输出的变量是一个有符号整型 (int 型)的变量。
类似地:
-
%s表示字符串。 -
%c表示字符。 -
%lf表示双精度浮点数 (double)。 -
%lld表示长整型 (long long)。根据系统不同,也可能是%I64d。 -
%u表示无符号整型 (unsigned int)。 -
%llu表示无符号长整型 (unsigned long long),也可能是%I64u
除了类型标识符以外,还有一些控制格式的方式。许多都不常用,选取两个常用的列举如下:
-
%1d表示长度为 1 的整型。在读入时,即使没有空格也可以逐位读入数字。在输出时,若指定的长度大于数字的位数,就会在数字前用空格填充。若指定的长度小于数字的位数,就没有效果。 -
%.6lf,用于输出,保留六位小数。
这两种运算符的相应地方都可以填入其他数字,例如 %.3lf 表示保留三位小数。
运算
算术运算符
| 运算符 | 功能 |
|---|---|
+ (单目) |
正 |
- (单目) |
负 |
* (双目) |
乘法 |
/ |
除法 |
% |
取模 |
+ (双目) |
加法 |
- (双目) |
减法 |
单目与双目运算符
算术运算符中有两个单目运算符(正、负)以及五个双目运算符(乘法、除法、取模、加法、减法),其中单目运算符的优先级最高。
其中取模运算符 % 意为计算两个整数相除得到的余数,即求余数。
而 - 为双目运算符时做减法运算符,如 2-1 ;为单目运算符时做负值运算符,如 -1 。
使用方法如下
yz=y-r*h
得到的 yz 的运算值遵循数学中加减乘除的优先规律,首先进行优先级高的运算,同优先级自左向右运算,括号提高优先级。
算术运算中的类型转换
对于双目算术运算符,当参与运算的两个变量类型相同时,不发生类型转换 ,运算结果将会用参与运算的变量的类型容纳,否则会发生类型转换,以使两个变量的类型一致。
转换的规则如下:
- 先将
char,short等类型提升至int(或unsigned int,取决于原类型的符号性)类型; - 若存在一个变量类型为
long double,会将另一变量转换为long double类型; - 否则,若存在一个变量类型为
double,会将另一变量转换为double类型; - 否则,若存在一个变量类型为
float,会将另一变量转换为float类型; - 否则(即参与运算的两个变量均为整数类型):
- 若两个变量符号性一致,则将位宽较小的类型转换为位宽较大的类型;
- 否则,若无符号变量的位宽不小于带符号变量的位宽,则将带符号数转换为无符号数对应的类型;
- 否则,若带符号操作数的类型能表示无符号操作数类型的所有值,则将无符号操作数转换为带符号操作数对应的类型;
- 否则,将带符号数转换为相对应的无符号类型。
例如,对于一个整型( int )变量 和另一个双精度浮点型( double )类型变量 :
-
x/3的结果将会是整型; -
x/3.0的结果将会是双精度浮点型; -
x/y的结果将会是双精度浮点型; -
x*1/3的结果将会是整型; -
x*1.0/3的结果将会是双精度浮点型;
自增/自减 运算符
有时我们需要让变量进行增加 1(自增)或者减少 1(自减),这时自增运算符 ++ 和自减运算符 -- 就派上用场了。
自增/自减运算符可放在变量前或变量后面,在变量前称为前缀,在变量后称为后缀,单独使用时前缀后缀无需特别区别,如果需要用到表达式的值则需注意
i = 100;
yz1 = i++; // yz1 = 100,先 yz1 = i,然后 i = i + 1
i = 100;
yz2 = ++i; // yz2 = 101,先 i = i + 1,然后赋值 yz2
i = 100;
yz3 = i--; // yz3 = 100,先赋值 yz3,然后 i = i - 1
i = 100;
yz4 = --i; // yz4 = 99,先 i = i - 1,然后赋值 yz4
复合赋值运算符
复合赋值运算符实际上是表达式的缩写形式。
yz = yz + 2 可以写成 yz += 2
yz = yz - 2 可以写成 yz -= 2
yz = yz * 2 可以写成 yz *= 2
yz = yz / 2 可以写成 yz /= 2
比较运算符
| 运算符 | 功能 |
|---|---|
> |
大于 |
>= |
大于等于 |
< |
小于 |
<= |
小于等于 |
== |
等于 |
!= |
不等于 |
其中特别需要注意的是要将等于运算符 == 和赋值运算符 = 区分开来,这在判断语句中尤为重要。
if(op=1) 与 if(op==1) 看起来类似,但实际功能却相差甚远。第一条语句是在对 op 进行赋值,若赋值为非 0 时为真值,表达式的条件始终是满足的,无法达到判断的作用;而第二条语句才是对 op 的值进行判断。
逻辑运算符
| 运算符 | 功能 |
|---|---|
&& |
逻辑与 |
| ` | |
! |
逻辑非 |
Result = op1 && op2; // 当 op1 与 op2 都为真时则 Result 为真
Result = op1 || op2; // 当 op1 或 op2 其中一个为真时则 Result 为真
Result = !op1; // 当 op1 为假时则 Result 为真
分支
if 语句
if (条件) {
主体;
}
if 语句通过对条件进行求值,若结果为真(非 0),执行语句,否则不执行。
如果主体中只有单个语句的话,花括号可以省略。
if...else 语句
if (条件) { 主体1;} else { 主体2;}
if...else 语句和 if 语句类似,else 不需要再写条件。当 if 语句的条件满足时会执行 if 里的语句,if 语句的条件不满足时会执行 else 里的语句。同样,当主体只有一条语句时,可以省略花括号。
else if 语句
if (条件1) { 主体1;} else if (条件2) { 主体2;} else if (条件3) { 主体3;} else { 主体4;}
else if 语句是 if 和 else 的组合,对多个条件进行判断并选择不同的语句分支。在最后一条的 else 语句不需要再写条件。例如,若条件 1 为真,执行主体 1,条件 3 为真而条件 1 和条件 2 都为假,执行主体 3,所有的条件都为假才执行主体 4。
实际上,这一个语句相当于第一个 if 的 else 分句只有一个 if 语句,就将花括号省略之后放在一起了。如果条件相互之间是并列关系,这样写可以让代码的逻辑更清晰。
switch 语句
switch (选择句) {
case 标签1:
主体1;
case 标签2:
主体2;
default:
主体3;
}
switch 语句执行时,先求出选择句的值,然后根据选择句的值选择相应的标签,从标签处开始执行。其中,选择句必须是一个整数类型表达式,而标签都必须是整数类型的常量。例如:
int i = 1; // 这里的 i 的数据类型是整型 ,满足整数类型的表达式的要求
switch (i) {
case 1:
printf(" i love yz");
}
char i = 'A';
// 这里的 i 的数据类型是字符型 ,但 char
// 也是属于整数的类型,满足整数类型的表达式的要求
switch (i) {
case 'A':
printf(" i love yz");
}
switch 语句中还要根据需求加入 break 语句进行中断,否则在对应的 case 被选择之后接下来的所有 case 里的语句和 default 里的语句都会被运行。具体例子可看下面的示例。
char i = 'B';
switch (i) {
case 'A':
printf(" i love yz");
break;
case 'B':
printf(" yz love yz");
default:
printf(" yz love me");
}
switch 的 case 分句中也可以选择性的加花括号。不过要注意的是,如果需要在 switch 语句中定义变量,花括号是必须要加的。例如:
char i = 'B';switch (i) { case 'A': { int i = 1, j = 2; printf("i\n"); ans = i + j; break; } case 'B': { int qwq = 3; printf("love\n"); ans = qwq * qwq; break; } default: { printf("yz\n"); }}
循环
for语句
for (初始化; 判断条件; 更新) { 循环体;}

读入 n 个数:
for (int i = 1; i <= n; i++) scanf("%d",&a[i]);
for 语句的三个部分中,任何一个部分都可以省略。其中,若省略了判断条件,相当于判断条件永远为真。
while 语句
while (判断条件) { 循环体;}

do...while 语句
do { 循环体;} while (判断条件);

与 while 语句的区别在于,do...while 语句是先执行循环体再进行判断的。
三种语句的联系
可能需要当面讲解
// for 语句for (statement1; statement2; statement3) { statement4;}// while 语句statement1;while (statement2) { statement4; statement3;}
// while 语句statement1;while (statement2) { statement1;}// do...while 语句do { statement1;} while (statement2);
while (1) { // do something...}for (;;) { // do something...}
可以看出,三种语句可以彼此代替,但一般来说,语句的选用遵守以下原则:
- 循环过程中有个固定的增加步骤(最常见的是枚举)时,使用 for 语句;
- 只确定循环的终止条件时,使用 while 语句;
- 使用 while 语句时,若要先执行循环体再进行判断,使用 do...while 语句。一般很少用到,常用场景是用户输入。
break 与 continue 语句
break 语句的作用是退出循环。
continue 语句的作用是跳过循环体的余下部分,回到循环的开头(for 语句的更新,while 语句的判断条件)。
for (int i = 1; i <= 10; ++i) { printf("%d\n",i); if (i > 3) break; if (i > 2) continue; printf("%d\n",i);}/*输出如下:112234*/
break 与 continue 语句均可在三种循环语句的循环体中使用。
一般来说,break 与 continue 语句用于让代码的逻辑更加清晰,例如:
// 逻辑较为不清晰,大括号层次复杂for (int i = 1; i <= n; ++i) { if (i != x) { for (int j = 1; j <= n; ++j) { if (j != x) { // do something... } } }}// 逻辑更加清晰,大括号层次简单明了for (int i = 1; i <= n; ++i) { if (i == x) continue; for (int j = 1; j <= n; ++j) { if (j == x) continue; // do something... }}
// for 语句判断条件复杂,没有体现“枚举”的本质for (int i = l; i <= r && i % 10 != 0; ++i) { // do something...}// for 语句用于枚举,break 用于“到何时为止”for (int i = l; i <= r; ++i) { if (i % 10 == 0) break; // do something...}
// 语句重复,顺序不自然
statement1;
while (statement3) {
statement2;
statement1;
}
// 没有重复语句,顺序自然
while (1) {
statement1;
if (!statement3) break;
statement2;
}
高级结构
数组
数组是存放相同类型对象的容器,数组中存放的对象没有名字,而是要通过其所在的位置访问。数组的大小是固定的,不能随意改变数组的长度。
定义数组
数组的声明形如 a[d],其中,a 是数组的名字,d 是数组中元素的个数。在编译时,d 应该是已知的,也就是说,d 应该是一个整型的常量表达式。
int d1 = 42;
const int d2 = 42;
int arr1[d1]; // 错误:d1 不是常量表达式
int arr2[d2]; // 正确:arr2 是一个长度为 42 的数组
不能将一个数组直接赋值给另一个数组:
int arr1[3];
int arr2 = arr1; // 错误
arr2 = arr1; // 错误
访问数组元素
可以通过下标运算符 [] 来访问数组内元素,数组的索引(即方括号中的值)从 0 开始。以一个包含 10 个元素的数组为例,它的索引为 0 到 9,而非 1 到 10。为了使用方便,我通常会将数组开大一点,不使用数组的第一个元素,从下标 1 开始访问数组元素。
例 1:从标准输入中读取一个整数$n$ ,再读取$n$个数,存入数组中。其中,$n \leq 1000$
#include int main(){ int a[1010], n;//可以定义大一点 用不到没关系 也别太离谱 scanf("%d",&n); int i ; for(i = 1; i <= n; i++)//从下标1开始 scanf("%d",&a[i]);}
例 2:(接例 1)求和数组 arr 中的元素,并输出和。满足数组中所有元素的和在int范围内
#include int main(){ int a[1010], n, sum = 0;//可以定义大一点 用不到没关系 也别太离谱 scanf("%d",&n); int i ; for(i = 1; i <= n; i++)//从下标1开始 scanf("%d",&a[i]); for(i = 1; i <= n; i++) sum += a[i]; printf("%d",sum);}
多维数组
多维数组的实质是「数组的数组」,即外层数组的元素是数组。一个二维数组需要两个维度来定义:数组的长度和数组内元素的长度。访问二维数组时需要写出两个索引:
int arr[3][4]; // 一个长度为 3 的数组,它的元素是「元素为 int 的长度为的 4 // 的数组」arr[2][1] = 1; // 访问二维数组
我们经常使用嵌套的 for 循环来处理二维数组。

const int maxn = 1001;int pic[maxn][maxn];int n, m;scanf("%d%d",&n,&m);for (int i = 1; i <= n; i++) for (int j = 1; j <= m; j++) scanf("%d",&pic[i][j]);
函数
函数的声明
编程中的函数(function)一般是若干语句的集合。我们也可以将其称作“子过程(subroutine)”。在编程中,如果有一些重复的过程,我们可以将其提取出来,形成一个函数。函数可以接收若干值,这叫做函数的参数。函数也可以返回某个值,这叫做函数的返回值。
声明一个函数,我们需要返回值类型、函数的名称,以及参数列表。
// 返回值类型 int// 函数的名称 some_function// 参数列表 int, intint some_function(int, int);
如上,我们声明了一个名为 some_function 的函数,它需要接收两个 int 类型的参数,返回值类型也为 int。可以认为,这个函数将会对传入的两个整数进行一些操作,并且返回一个同样类型的结果。
实现函数:编写函数的定义
只有函数的声明(declaration)还不够,他只能让我们在调用时能够得知函数的 接口 类型(即接收什么数据、返回什么数据),但其缺乏具体的内部实现,也就是函数的 定义(definition)。我们可以在 声明之后的其他地方 编写代码 实现(implement)这个函数(也可以在另外的文件中实现,但是需要将分别编译后的文件在链接时一并给出)。
如果函数有返回值,则需要通过 return 语句,将值返回给调用方。函数一旦执行到 return 语句,则直接结束当前函数,不再执行后续的语句。
int some_function(int, int); // 声明/* some other code here... */int some_function(int x, int y) { // 定义 int result = 2 * x + y; return result; result = 3; // 这条语句不会被执行}
如果函数不需要有返回值,则将函数的返回值类型标为 void;如果函数不需要参数,则可以将参数列表置空。同样,无返回值的函数执行到 return; 语句也会结束执行。
void saylove(){ printf("love yz\n");}
函数的调用
和变量一样,函数需要先被声明,才能使用。使用函数的行为,叫做“调用(call)”。我们可以在任何函数内部调用其他函数,包括这个函数自身。函数调用自身的行为,称为 递归(recursion)。
在大多数语言中,调用函数的写法,是 函数名称加上一对括号 (),如 yz()。如果函数需要参数,则我们将其需要的参数按顺序填写在括号中,以逗号间隔,如 yz(1, 2)。函数的调用也是一个表达式,函数的返回值 就是 表达式的值。
函数声明时候写出的参数,可以理解为在函数 当前次调用的内部 可以使用的变量,这些变量的值由调用处传入的值初始化。看下面这个例子:
void foo(int x, int y) {
x = x * 2;
y = y + 3;
}
/* ... */
a = 1;
b = 1;
// 调用前:a = 1, b = 1
foo(a, b); // 调用 foo
// 调用后:a = 1, b = 1
在上面的例子中,yz(a, b) 是一次对 foo 的调用。调用时,yz 中的 x 和 y 变量,分别由调用处 a 和 b 的值初始化。因此,在 yz 中对变量 x 和 y 的修改,并不会影响到调用处的变量的值。
如果我们需要在函数(子过程)中修改变量的值,则需要采用“传引用”的方式。
void foo(int& x, int& y) {
x = x * 2;
y = y + 3;
}
/* ... */
a = 1;
b = 1;
// 调用前:a = 1, b = 1
foo(a, b); // 调用 foo
// 调用后:a = 2, b = 4
上述代码中,我们看到函数参数列表中的“int”后面添加了一个“&(and 符号)”,这表示对于 int 类型的 引用(reference)。在调用 foo 时,调用处 a 和 b 变量分别初始化了 foo 中两个对 int 类型的引用 x 和 y。在 foo 中的 x 和 y,可以理解为调用处 a 和 b 变量的“别名”,即 foo 中对 x 和 y 的操作,就是对调用处 a 和 b 的操作。
结构体
结构体(struct),可以看做是一系列称为成员元素的组合体。
可以看做是自定义的数据类型。
定义结构
为了定义结构,必须使用 struct 语句。struct 语句定义了一个包含多个成员的新的数据类型,struct 语句的格式如下:
struct tag { member-list member-list member-list ...} variable-list ;
tag 是结构体标签。
member-list 是标准的变量定义,比如 int i; 或者 float f,或者其他有效的变量定义。
variable-list 结构变量,定义在结构的末尾,最后一个分号之前,您可以指定一个或多个结构变量。下面是声明 Book 结构的方式:
struct Books{ char title[50]; char author[50]; char subject[100]; int book_id;} book;
在一般情况下,tag、member-list、variable-list 这 3 部分至少要出现 2 个。以下为实例:
//此声明声明了拥有3个成员的结构体,分别为整型的a,字符型的b和双精度的c
//同时又声明了结构体变量s1
//这个结构体并没有标明其标签
struct
{
int a;
char b;
double c;
} s1;
//此声明声明了拥有3个成员的结构体,分别为整型的a,字符型的b和双精度的c
//结构体的标签被命名为SIMPLE,没有声明变量
struct SIMPLE
{
int a;
char b;
double c;
};
//用SIMPLE标签的结构体,另外声明了变量t1、t2、t3
struct SIMPLE t1, t2[20], *t3;
//也可以用typedef创建新类型
typedef struct
{
int a;
char b;
double c;
} Simple2;
//现在可以用Simple2作为类型声明新的结构体变量
Simple2 u1, u2[20], *u3;
结构体变量的初始化
#include
struct Books
{
char title[50];
char author[50];
char subject[100];
int book_id;
} book = {"C 语言", "RUNOOB", "编程语言", 123456};
int main()
{
printf("title : %s\nauthor: %s\nsubject: %s\nbook_id: %d\n", book.title, book.author, book.subject, book.book_id);
}
/*
title : C 语言
author: RUNOOB
subject: 编程语言
book_id: 123456
*/
访问结构成员
为了访问结构的成员,我们使用成员访问运算符(.)。成员访问运算符是结构变量名称和我们要访问的结构成员之间的一个句号。您可以使用 struct 关键字来定义结构类型的变量。下面的实例演示了结构的用法:
#include #include struct Books{ char title[50]; char author[50]; char subject[100]; int book_id;}; int main( ){ struct Books Book1; /* 声明 Book1,类型为 Books */ struct Books Book2; /* 声明 Book2,类型为 Books */ /* Book1 详述 */ strcpy( Book1.title, "C Programming"); strcpy( Book1.author, "Nuha Ali"); strcpy( Book1.subject, "C Programming Tutorial"); Book1.book_id = 6495407; /* Book2 详述 */ strcpy( Book2.title, "Telecom Billing"); strcpy( Book2.author, "Zara Ali"); strcpy( Book2.subject, "Telecom Billing Tutorial"); Book2.book_id = 6495700; /* 输出 Book1 信息 */ printf( "Book 1 title : %s\n", Book1.title); printf( "Book 1 author : %s\n", Book1.author); printf( "Book 1 subject : %s\n", Book1.subject); printf( "Book 1 book_id : %d\n", Book1.book_id); /* 输出 Book2 信息 */ printf( "Book 2 title : %s\n", Book2.title); printf( "Book 2 author : %s\n", Book2.author); printf( "Book 2 subject : %s\n", Book2.subject); printf( "Book 2 book_id : %d\n", Book2.book_id); return 0;}/*Book 1 title : C ProgrammingBook 1 author : Nuha AliBook 1 subject : C Programming TutorialBook 1 book_id : 6495407Book 2 title : Telecom BillingBook 2 author : Zara AliBook 2 subject : Telecom Billing TutorialBook 2 book_id : 6495700*/
指针
变量的地址、指针
在程序中,我们的数据都有其存储的地址。在程序每次的实际运行过程中,变量在物理内存中的存储位置不尽相同。不过,我们仍能够在编程时,通过一定的语句,来取得数据在内存中的地址。
地址也是数据。存放地址所用的变量类型有一个特殊的名字,叫做“指针变量”,有时也简称做“指针”。
地址只是一个刻度一般的数据,为了针对不同类型的数据,“指针变量”也有不同的类型,比如,可以有 int 类型的指针变量,其中存储的地址(即指针变量存储的数值)对应一块大小为 32 位的空间的起始地址;有 char 类型的指针变量,其中存储的地址对应一块 8 位的空间的起始地址。
事实上,用户也可以声明指向指针变量的指针变量。
指针的声明与使用
#include int main (){ int yrh = 10; int *p; // 定义指针变量 p = &yrh; printf("yrh 变量的地址: %p\n", p); return 0;}/*yrh 变量的地址: 0x7ffeeaae08d8*/
什么是指针?
指针也就是内存地址,指针变量是用来存放内存地址的变量。就像其他变量或常量一样,您必须在使用指针存储其他变量地址之前,对其进行声明。指针变量声明的一般形式为:
type *var-name;
在这里,type 是指针的基类型,它必须是一个有效的 C 数据类型,var-name 是指针变量的名称。用来声明指针的星号 ***** 与乘法中使用的星号是相同的。但是,在这个语句中,星号是用来指定一个变量是指针。以下是有效的指针声明:
int *ip; /* 一个整型的指针 */double *dp; /* 一个 double 型的指针 */float *fp; /* 一个浮点型的指针 */char *ch; /* 一个字符型的指针 */
所有实际数据类型,不管是整型、浮点型、字符型,还是其他的数据类型,对应指针的值的类型都是一样的,都是一个代表内存地址的长的十六进制数。
不同数据类型的指针之间唯一的不同是,指针所指向的变量或常量的数据类型不同。
如何使用指针?
使用指针时会频繁进行以下几个操作:定义一个指针变量、把变量地址赋值给指针、访问指针变量中可用地址的值。这些是通过使用一元运算符 ***** 来返回位于操作数所指定地址的变量的值。下面的实例涉及到了这些操作:
#include int main (){ int var = 20; /* 实际变量的声明 */ int *ip; /* 指针变量的声明 */ ip = &var; /* 在指针变量中存储 var 的地址 */ printf("var 变量的地址: %p\n", &var ); /* 在指针变量中存储的地址 */ printf("ip 变量存储的地址: %p\n", ip ); /* 使用指针访问值 */ printf("*ip 变量的值: %d\n", *ip ); return 0;}/*var 变量的地址: 0x7ffeeef168d8ip 变量存储的地址: 0x7ffeeef168d8*ip 变量的值: 20*/
C 中的 NULL 指针
在变量声明的时候,如果没有确切的地址可以赋值,为指针变量赋一个 NULL 值是一个良好的编程习惯。赋为 NULL 值的指针被称为空指针。
NULL 指针是一个定义在标准库中的值为零的常量
#include int main (){ int *ptr = NULL; printf("ptr 的地址是 %p\n", ptr ); return 0;}/*ptr 的地址是 0x0*/
在大多数的操作系统上,程序不允许访问地址为 0 的内存,因为该内存是操作系统保留的。然而,内存地址 0 有特别重要的意义,它表明该指针不指向一个可访问的内存位置。但按照惯例,如果指针包含空值(零值),则假定它不指向任何东西。
如需检查一个空指针,可以使用 if 语句,如下所示:
if(ptr) /* 如果 p 非空,则完成 */if(!ptr) /* 如果 p 为空,则完成 */
指针的算术运算
C 指针是一个用数值表示的地址。因此,您可以对指针执行算术运算。可以对指针进行四种算术运算:++、--、+、-。
假设 ptr 是一个指向地址 1000 的整型指针,是一个 32 位的整数,让我们对该指针执行下列的算术运算:
ptr++
在执行完上述的运算之后,ptr 将指向位置 1004,因为 ptr 每增加一次,它都将指向下一个整数位置,即当前位置往后移 4 字节。这个运算会在不影响内存位置中实际值的情况下,移动指针到下一个内存位置。如果 ptr 指向一个地址为 1000 的字符,上面的运算会导致指针指向位置 1001,因为下一个字符位置是在 1001。
- 指针的每一次递增,它其实会指向下一个元素的存储单元。
- 指针的每一次递减,它都会指向前一个元素的存储单元。
- 指针在递增和递减时跳跃的字节数取决于指针所指向变量数据类型长度,比如 int 就是 4 个字节。
递增一个指针
#include const int MAX = 3; int main (){ int var[] = {10, 100, 200}; int i, *ptr; /* 指针中的数组地址 */ ptr = var; for ( i = 0; i < MAX; i++) { printf("存储地址:var[%d] = %p\n", i, ptr ); printf("存储值:var[%d] = %d\n", i, *ptr ); /* 指向下一个位置 */ ptr++; } return 0;}/*存储地址:var[0] = e4a298cc存储值:var[0] = 10存储地址:var[1] = e4a298d0存储值:var[1] = 100存储地址:var[2] = e4a298d4存储值:var[2] = 200*/
递减一个指针
#include const int MAX = 3; int main (){ int var[] = {10, 100, 200}; int i, *ptr; /* 指针中最后一个元素的地址 */ ptr = &var[MAX-1]; for ( i = MAX; i > 0; i--) { printf("存储地址:var[%d] = %p\n", i-1, ptr ); printf("存储值:var[%d] = %d\n", i-1, *ptr ); /* 指向下一个位置 */ ptr--; } return 0;}/*存储地址:var[2] = 518a0ae4存储值:var[2] = 200存储地址:var[1] = 518a0ae0存储值:var[1] = 100存储地址:var[0] = 518a0adc存储值:var[0] = 10*/
指针的比较
指针可以用关系运算符进行比较,如 ==、< 和 >。如果 p1 和 p2 指向两个相关的变量,比如同一个数组中的不同元素,则可对 p1 和 p2 进行大小比较。
下面的程序修改了上面的实例,只要变量指针所指向的地址小于或等于数组的最后一个元素的地址 &var[MAX - 1],则把变量指针进行递增:
#include const int MAX = 3; int main (){ int var[] = {10, 100, 200}; int i, *ptr; /* 指针中第一个元素的地址 */ ptr = var; i = 0; while ( ptr <= &var[MAX - 1] ) { printf("存储地址:var[%d] = %p\n", i, ptr ); printf("存储值:var[%d] = %d\n", i, *ptr ); /* 指向上一个位置 */ ptr++; i++; } return 0;}/*存储地址:var[0] = 0x7ffeee2368cc存储值:var[0] = 10存储地址:var[1] = 0x7ffeee2368d0存储值:var[1] = 100存储地址:var[2] = 0x7ffeee2368d4存储值:var[2] = 200*/
指针数组
我们想要让数组存储指向 int 或 char 或其他数据类型的指针。下面是一个指向整数的指针数组的声明:
int *ptr[MAX];
在这里,把 ptr 声明为一个数组,由 MAX 个整数指针组成。因此,ptr 中的每个元素,都是一个指向 int 值的指针。下面的实例用到了三个整数,它们将存储在一个指针数组中,如下所示:
#include const int MAX = 3; int main (){ int var[] = {10, 100, 200}; int i, *ptr[MAX]; for ( i = 0; i < MAX; i++) { ptr[i] = &var[i]; /* 赋值为整数的地址 */ } for ( i = 0; i < MAX; i++) { printf("Value of var[%d] = %d\n", i, *ptr[i] ); } return 0;}/*Value of var[0] = 10Value of var[1] = 100Value of var[2] = 200*/
可以用一个指向字符的指针数组来存储一个字符串列表,如下:
#include const int MAX = 4; int main (){ const char *names[] = { "yrh", "love", "yz", "!", }; int i = 0; for ( i = 0; i < MAX; i++) { printf("Value of names[%d] = %s\n", i, names[i] ); } return 0;}/*Value of names[0] = yrhValue of names[1] = loveValue of names[2] = yzValue of names[3] = !*/
指向指针的指针
指向指针的指针是一种多级间接寻址的形式,或者说是一个指针链。通常,一个指针包含一个变量的地址。当我们定义一个指向指针的指针时,第一个指针包含了第二个指针的地址,第二个指针指向包含实际值的位置。

一个指向指针的指针变量必须如下声明,即在变量名前放置两个星号。例如,下面声明了一个指向 int 类型指针的指针:
int **var;
当一个目标值被一个指针间接指向到另一个指针时,访问这个值需要使用两个星号运算符,如下面实例所示:
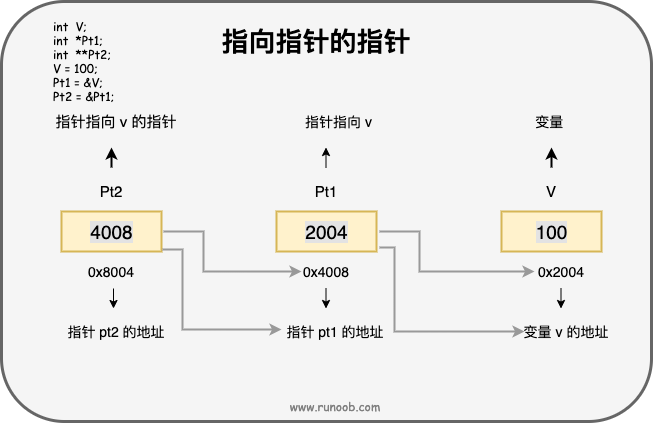
#include int main (){ int V; int *Pt1; int **Pt2; V = 100; /* 获取 V 的地址 */ Pt1 = &V; /* 使用运算符 & 获取 Pt1 的地址 */ Pt2 = &Pt1; /* 使用 pptr 获取值 */ printf("var = %d\n", V ); printf("Pt1 = %p\n", Pt1 ); printf("*Pt1 = %d\n", *Pt1 ); printf("Pt2 = %p\n", Pt2 ); printf("**Pt2 = %d\n", **Pt2); return 0;}/*var = 100Pt1 = 0x7ffee2d5e8d8*Pt1 = 100Pt2 = 0x7ffee2d5e8d0**Pt2 = 100*/
传递指针给函数
C 语言允许传递指针给函数,只需要简单地声明函数参数为指针类型即可。
#include
#include
void getSeconds(unsigned long *par);
int main ()
{
unsigned long sec;
getSeconds( &sec );
/* 输出实际值 */
printf("Number of seconds: %ld\n", sec );
return 0;
}
void getSeconds(unsigned long *par)
{
/* 获取当前的秒数 */
*par = time( NULL );
return;
}
/*
Number of seconds :1294450468
*/
能接受指针作为参数的函数,也能接受数组作为参数,如下所示:
#include
/* 函数声明 */
double getAverage(int *arr, int size);
int main ()
{
/* 带有 5 个元素的整型数组 */
int balance[5] = {1000, 2, 3, 17, 50};
double avg;
/* 传递一个指向数组的指针作为参数 */
avg = getAverage( balance, 5 ) ;
/* 输出返回值 */
printf("Average value is: %f\n", avg );
return 0;
}
double getAverage(int *arr, int size)
{
int i, sum = 0;
double avg;
for (i = 0; i < size; ++i)
{
sum += arr[i];
}
avg = (double)sum / size;
return avg;
}
/*
Average value is: 214.40000
*/
从函数返回指针
C 允许从函数返回指针。为了做到这点,必须声明一个返回指针的函数,如下所示:
int * myFunction(){...}
另外,C 语言不支持在调用函数时返回局部变量的地址,除非定义局部变量为 static 变量。
它会生成 10 个随机数,并使用表示指针的数组名(即第一个数组元素的地址)来返回它们
#include
#include
#include
/* 要生成和返回随机数的函数 */
int * getRandom( )
{
static int r[10];
int i;
/* 设置种子 */
srand( (unsigned)time( NULL ) );
for ( i = 0; i < 10; ++i)
{
r[i] = rand();
printf("%d\n", r[i] );
}
return r;
}
/* 要调用上面定义函数的主函数 */
int main ()
{
/* 一个指向整数的指针 */
int *p;
int i;
p = getRandom();
for ( i = 0; i < 10; i++ )
{
printf("*(p + [%d]) : %d\n", i, *(p + i) );
}
return 0;
}
/*
1523198053
1187214107
1108300978
430494959
1421301276
930971084
123250484
106932140
1604461820
149169022
*(p + [0]) : 1523198053
*(p + [1]) : 1187214107
*(p + [2]) : 1108300978
*(p + [3]) : 430494959
*(p + [4]) : 1421301276
*(p + [5]) : 930971084
*(p + [6]) : 123250484
*(p + [7]) : 106932140
*(p + [8]) : 1604461820
*(p + [9]) : 149169022
*/
字符串
定义
在 C 语言中,字符串实际上是使用 null 字符 \0 终止的一维字符数组。因此,一个以 null 结尾的字符串,包含了组成字符串的字符。
char yrh[7] = {'l','o','v','e','y','z','\0'};
依据数组初始化规则,可以把上面的语句写成以下语句:
char yrh[] = "loveyz";
操作字符串的函数:
#include
| 序号 | 函数 & 目的 |
|---|---|
| 1 | strcpy(s1, s2); 复制字符串 s2 到字符串 s1。 |
| 2 | strcat(s1, s2); 连接字符串 s2 到字符串 s1 的末尾。 |
| 3 | strlen(s1); 返回字符串 s1 的长度。 |
| 4 | strcmp(s1, s2); 如果 s1 和 s2 是相同的,则返回 0;如果 s1 |
| 5 | strchr(s1, ch); 返回一个指针,指向字符串 s1 中字符 ch 的第一次出现的位置。 |
| 6 | strstr(s1, s2); 返回一个指针,指向字符串 s1 中字符串 s2 的第一次出现的位置。 |
#include
#include
int main ()
{
char str1[14] = "yrh";
char str2[14] = "yz";
char str3[14];
int len ;
/* 复制 str1 到 str3 */
strcpy(str3, str1);
printf("strcpy( str3, str1) : %s\n", str3 );
/* 连接 str1 和 str2 */
strcat( str1, str2);
printf("strcat( str1, str2): %s\n", str1 );
/* 连接后,str1 的总长度 */
len = strlen(str1);
printf("strlen(str1) : %d\n", len );
return 0;
}
排序算法
冒泡排序
#include
void bubble_sort(int arr[], int len) {
int i, j, temp;
for (i = 0; i < len - 1; i++)
for (j = 0; j < len - 1 - i; j++)
if (arr[j] > arr[j + 1]) {
temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
int main() {
int arr[] = { 22, 34, 3, 32, 82, 55, 89, 50, 37, 5, 64, 35, 9, 70 };
int len = (int) sizeof(arr) / sizeof(*arr);
bubble_sort(arr, len);
int i;
for (i = 0; i < len; i++)
printf("%d ", arr[i]);
return 0;
}
选择排序
void selection_sort(int a[], int len)
{
int i,j,temp;
for (i = 0 ; i < len - 1 ; i++)
{
int min = i; // 记录最小值,第一个元素默认最小
for (j = i + 1; j < len; j++) // 访问未排序的元素
{
if (a[j] < a[min]) // 找到目前最小值
{
min = j; // 记录最小值
}
}
if(min != i)
{
temp=a[min]; // 交换两个变量
a[min]=a[i];
a[i]=temp;
}
/* swap(&a[min], &a[i]); */ // 使用自定义函数交換
}
}
/*
void swap(int *a,int *b) // 交换两个变量
{
int temp = *a;
*a = *b;
*b = temp;
}
*/
插入排序
void insertion_sort(int arr[], int len){
int i,j,temp;
for (i=1;i0 && arr[j-1]>temp;j--)
arr[j] = arr[j-1];
arr[j] = temp;
}
}

羡慕您女朋友