
本文是在学习Golang的时候整理的一些内容,本文参考了 the-way-to-go 和 Go语言精进之路 正在补充...... 未完工
安装
截止发文,最新的Go版本是1.21.2, 在Linux下下载方式
$ wget https://go.dev/dl/go1.21.2.linux-amd64.tar.gz
$ tar -zxvf go1.21.2.linux-amd64.tar.gz
$ sudo mv go /usr/local/
$ go version
go version go1.21.1 linux/amd64
自从Go 1.11开始,Go提供了Go Moudle 机制,抛弃了$GOPATH等操作,如果没有proxy,推荐设置以下环境变量
$ go env -w GOPROXY=https://goproxy.cn,direct
Hello World
新建一个main.go 写入
package main
import "fmt"
func main(){
fmt.Println("hello world!")
}
执行go run main.go 或者 go run . 在bash里面将会看到
$go run .
hello world!
如果启用了 Go Moudle 机制, 则需要初始化mod go mod init
特别的,执行go run main.go 其实是执行两步
- go build main.go // 编译成二进制可执行文件
- ./main // 执行该程序
变量&数据类型
变量 Variable
Go语言是静态类型的,变量声明必须明确,显著的: Go语言的类型是在变量后面的, 比如int a = 1
var a int
var a int = 1
var a = 1
对于var a = 1 因为 1 是int 类型的, 所以赋值的时候, a被自动确定成int 类型, 这种方式还有一种表达
a := 1
msg := "hello world"
简单类型
- 空值:
nil - 整数类型:
intint8int16int32int64uint8uint16 - 浮点数:
float32float64 - 字节类型:
byte - 字符串:
string - 布尔:
boolean
字符串
Go语言中,字符串使用UTF8 编码,好处是 如果基本都是英文,每个字符占1byte 和 ASCII 编码是一样的,如果是中文,一般是3byte
特别的在处理有中文的字符串的时候,是有区别的
package main
import "fmt"
func main() {
str1 := "hello world"
str2 := "go语言"
fmt.Println(len(str1), len(str2)) // 11 8
fmt.Println(string(str1[2]), string(str2[2]))// l è
}
因为字符串是以byte数组形式存储的,所以str[2] 并不等于 语 len(str2) 的长度是2 + 6 = 8
正确的处理方式是把字符串转换成rune, 在[]rune 中,字符串的每个字符都是int32来表示的,
package main
import "fmt"
func main() {
str1 := "hello world"
str2 := "go语言"
fmt.Println(len(str1), len(str2)) // 11 8
fmt.Println(string(str1[2]), string(str2[2])) // l è
runeTest := []rune(str2)
fmt.Println(len(runeTest), string(runeTest[2]))// 4 语
}
数组和切片
声明数组
var arr [5]int
var arr2 [5][5]int
声明的时候初始化
var arr = [5]int{1,2,3,4,5}
arr := [5]int{1,2,3,4,5}
数组的长度不能改变, 如果想拼接两个数组,或是获取子数组,需要使用切片。 切片是数组的抽象。切片使用数组作为底层结构。切片包含三个组件:容量、长度、指向底层数组的指针, 切片可以随时扩展。
声明切片
slice1 := make([]int, 0) // 长度为0的切片
slice2 := male([]int, 3, 5) /// [0,0,0] 长度为3 容量为5的切片
使用切片
slice2 = append(slice2, 1,3,4,5) // [0,0,0,1,3,4,5]
sub1 := slice2[3:] // [1,3,4,5]
sub2 := slice2[:3] // [0,0,0]
sub3 := slice2[1:4] // [0,0,1]
union := append(sub1, sub2...)
- 声明切片的时候可以设置容量大小,为切片预留分配空间。在实际使用中,如果切片容量不够,会自动扩展。
-
sub2...是切片的解构写法,把切片解构成N个独立的元素,
切片的复制
slice1 := make([]int, 3, 5)
slice2 := make([]int, len(slice2), cap(slice2))
copy(slice2, slice1) // 注意是后面的拷贝给前面
还有一种方法
slice3 := slice2[:]
但是这样会有一个缺点, 这是浅拷贝, slice3和slice2是同一个切片,无论改动哪个,另一个会跟着变。
排序
map
Go语言的map类似Java的Hashmap,Python的Dict, 是一种Key-Value的数据结构
// 仅声明
mp1 := make(map[string]int)
// 声明时初始化
mp2 := make(map[string]int){
"yrh":1,
"sb":2,
}
mp1["yrh"] = 2
定义
map[keyType] valueType
map是引用类型,初始值是nil,定义时必须用make来创建 必须要申请空间,所有的引用类型都要这么做
var m map[string]string
m = make(map[string]string)
//或者
m := make(map[string]string)
Use
//赋值
m["name"] = "yrh"
m["type"] = "sb"
// 循环遍历
for key := range m{
fmt.Println(key, m[key])
}
// 删除元素
delete(m, "name")
// ps: 取值的时候m[key], 假如m[key]不存在, 会返回value的默认值,比如int就返回0
// 判断元素是否存在
if value, ok := m[key]; ok{
fmt.Println("success")
}else{
fmt.Println("error")
}
map元素修改
map是不能拷贝的,如果想拷贝一个map, 有且只有一个办法是循环拷贝
originMap := make(map[int]int)
originMap[1] = 1
originMap[2] = 2
targetMap := make(map[int]int)
for k,v := range originMap{
target[k] = v
}
如果map 中有指针,还得考虑深拷贝的过程
originMap := make(map[int]*int)
num := 1
originMap[1] = &num
targetMap := make(map[int]*int)
for k,v := range originMap{
tempNum := *value
targetNum[key] = &tempNum
}
如果要更新map的值,直接执行赋值操作即可
m[1] = 2
如果value 是一个结构体,那么可以直接替换结构体,但是没法更新结构体内部的值
originMap := make(map[int]Student)
originMap[1] = Student{name:"yrh",age:21}
originMap[1].age = 30
// 会报错Cannot assign to originMap[1].age
在issue-3117,有回答解释了这一点
简单的来说map不是一个安全的并发结构,所以不能修改他在结构体中的值
The two cases really are different. Given a map holding a struct
m[0] = s
is a write.
m[0].f = 1
is a read-modify-write. That is, we can implement
m[0] = s
by passing 0 and s to the map insert routine. That doesn't work for
m[0].f
Instead we have to fetch a pointer, as you suggest, and assign through the pointer.
Right now maps are unsafe when GOMAXPROCS > 1 because multiple threads writing to the
map simultaneously can corrupt the data structure. This is an unfortunate violation of
Go's general memory safeness. This suggests that we will want to implement a
possibly-optional safe mode, in which the map is locked during access. That will work
straightforwardly with the current semantics. But it won't work with your proposed
addition.
That said, there is another possible implementation. We could pass in the key, an
offset into the value type, the size of the value we are passing, and the value we are
passing.
A more serious issue: if we permit field access, can we justify prohibiting method
access?
m[0].M()
But method access really does require addressability.
And let's not ignore
m[0]++
m[0][:]
所以怎么解决呢?
- 创建个临时变量,做拷贝
temp := m[1]
temp.age = 30
m[1] = temp
- 直接用指针
originPointMap := make(map[int]*Student)
originPointMap[1] = &Student{name:"yrh",age:21}
originPointMap[1].age = 30
并发问题
Go语言的map并发读是没有问题的,但是并发写就不行了,因为线程不安全,会发生竞态问题。
Go语言提供了一个叫Sync.Map的封装结构供大家使用,我还没用过先不写了(
函数
简介
Go语言的基本函数是这样的,以func为关键词标记函数
func myFunc(a int){}
其中形参可以有多个,类型相同的时候可以省略
func myFunc(a, b int, c string){}
上述的函数都没有返回值,没有返回值的函数要么是引用传递,要么用于单元测试
返回值标志在函数第一个括号后面,由于Go语言是强类型语言,和python不同,要写出返回值类型。
func myFunc(a, b int) int{
return a + b
}
如果有多个返回值,需要用括号括起来
func myFunc(a, b int) (int, int){
return b, a
}
上面的返回值全是匿名的,我们可以给他一个名字,函数中不用定义返回值。
func myFunc(a, b int) (res int){
res = a + b
return
}
值传递,引用传递
在值传递的时候,是深拷贝,和其他语言是一样的,如果要在函数内修改参数值,需要引用传递,传入指针。
func myFunc(a, b *int){
temp := *a
*a = *b
*b = temp
}
myFunc(&x, &y)
上面的例子是传入的指针,还有一种是引用类型,和指针的区别是不需要*和&, 对他的修改会改动到原变量上。
Go语言只有三种引用类型:Slice map channel
Next
和javaScript一样,Go语言也有把函数当做参数传递的语法。
像这样,myFunc函数的形参中里面有一个do的函数,但是需要提前指定do函数有什么参数和返回值
func myFunc(a, b int, do func(int, int) int){
fmt.Println(do(a,b))
}
do(a,b)是在myFunc内部掉用的
func add(a, b int) int{
return a + b
}
func sub(a, b int) int{
return a - b
}
因为符合do函数的定义要求,所以可以这么调用
myFunc(a, b, add)
myFunc(a, b, sub)
这种模式叫做
装饰器模式 Decorator Pattern:允许向一个现有的对象添加新的功能,同时又不改变其结构。
匿名函数和闭包
匿名函数
上面我们说到了装饰器模式,即在不改动原有函数内部实现的情况下,改变函数实现细节。 A Sample Example:
f := func(i int){
fmt.Println(i)
}
f(1)
跟JavaScript是一样的。
闭包
有时候,我们需要定义很多全部变量来共享数据,这种变量一旦多了,就会很难看,会污染环境,于是有一种东西叫做闭包,来解决这种问题。
闭包的简单实现,就是把函数定义在函数的内部,并当做返回值返回
func myFunc() func() {
count := 0
return func(){
count ++
fmt.Println(count)
}
}
具体怎么用呢? 我先定义两个函数c1 c2 他们就是myFunc()的返回值,类型都是匿名函数。
c1, c2 = myFunc(), myFunc()
然后我们运行来看一下
c1, c2 := myFunc(), myFunc()
c1()
c1()
c1()
c2()
c1()
/*
1
2
3
1
4
*/
可以看到在调用c2的时候 c1是不受影响的。
这是因为各个函数独立使用一套自己的内部变量,互不影响,所以闭包可以在做测试的时候使用。
- 好处:防止变量污染
- 坏处:延长局部变量和函数的声明周期,增加了
gc的压力
闭包形式2
闭包在定义之后可以立即被调用
func(){}()
闭包的bug
Go语言中,创建一个协程,类似于子进程,非常容易,只需要在语句前面加一个go关键词即可。
观察下面函数
for i := 0; i <= 3; i++ {
fmt.Println("Outside", i)
go func() {
fmt.Println("Inside", i)
}()
}
time.Sleep(time.Second)
/*
Outside 0
Outside 1
Outside 2
Outside 3
Inside 4
Inside 4
Inside 4
Inside 4
*/
可以观察到Inside 全是输出的 4。
因为Goroutine是异步的,并不是同步的,所以等外面结束了,Goroutine才启动,导致全部输出的i = 4
解决办法: 创建副本,给匿名函数加一个参数,参数传过来自动生成副本
for i := 0; i <= 3; i++ {
fmt.Println("Outside", i)
go func(tmp int) {
fmt.Println("Inside", tmp)
}(i)
}
time.Sleep(time.Second)
/*
Outside 0
Outside 1
Outside 2
Outside 3
Inside 3
Inside 2
Inside 0
Inside 1
*/
语法 & 语法进阶
循环
for的第一种方式
nums := []int{1,2,3,4,5}
for i := 0; i < len(nums); i++{
//do sometings
}
for的第二种方式
a,b := 1,5
for a < b{
a ++
// do somethings
}
for的第三种方式
nums := []int{1,2,3,4,5}
for index, value := range nums{
//do somethings
}
for _, value := range nums{}
for index := range nums{}
死循环
for {}
结构体
简介
和c++的结构体类似,
type myStruct struct{
name string
age int
}
var mystruct myStruct
go中的类
一些面向对象的语言,会有类这一概念,但是Go语言里面没有。
Go语言用一种特殊的方法,把结构体看做成一个类。
一个成熟的类,具备成员变量和成员函数,结构体本身就有成员变量, 再给他绑定上成员函数,就可以看成是一个类。
type Student struct{
name string
}
func (p Student) sayHello(){
fmt.Println("hello, my Name is ", p.name)
}
接口与多态
接口
和java一样,可以把一堆有共性的方法定义在一起,但是比java灵活的是,不需要显式实现接口,即不需要implement interface
type myInterface interface{
eat() string
play() string
}
type myStruct struct{
name string
}
func (p myStruct) eat() string{
return p.name + " is eating"
}
func (p myStruct) play() string{
return p.name + " is playing"
}
var test myInterface
test = new(myStruct)
fmt.Println(test.eat(), test.paly())
PS: 这里的new和C++不一样的是,不需要手动释放内存,它是由Go语言的垃圾处理机来释放内存的。
注意,必须实现了接口的全部方法才算实现了这个接口!
异常处理
异常处理的思想
在 go 语言里是没有 try catch 的概念的,因为 try catch 会消耗更多资源,而且不管从 try 里面哪个地方跳出来,都是对代码正常结构的一种破坏
所以 go 语言的设计思想中主张
- 如果一个函数可能出现异常,那么应该把异常作为返回值,没有异常就返回 nil
- 每次调用可能出现异常的函数时,都应该主动进行检查,并做出反应,这种 if 语句术语叫卫述语句
所以异常应该总是掌握在我们的手上,保证每次操作产生的影响达到最小,保证程序即使部分地方出现问题,也不会影响整个程序的运行,及时的处理异常,这样就可以减轻上层处理异常的压力。 同时也不要让未知的异常使你的程序崩溃。
异常的形式
我们通常是这样的
func Demo() (int, error)
我们通常这么处理异常,使用卫述语句
_, err := Demo()
if err != nil{
}else{}
自定义异常
func division(a, b int) (int, error){
if(b == 0){
return -1, errors.New("除数不能为零")
}
return a/b, nil
}
a, b := 6, 0
ans, err := division(a,b)
if err != nil{
fmt.Println(err.Error())
}
观察代码我们可以发现两个点
- 创建一个异常
errors.New() - 获取异常信息
err.Error()
但是errors.New()不支持格式化字符串,所以通常不建议使用,我们通常是用的是fmt.Errorf
err = fmt.Errorf("产生了一个 %v 异常", "sb")
defer
Go语言中有一种延迟调用语句是defer,他是在函数返回时才会被调用,如果有多个defer语句,那么他会逆序调用。
defer fmt.Println("1");
defer fmt.Println("2");
fmt.Println("3")
/*
3
2
1
*/
defer的好处是,在程序执行结束,甚至是崩溃之后,仍然会被调用的语句,通常来执行一些告别操作,比如 关闭链接、释放资源等
- 并发时释放共享锁
- 延迟释放文件句柄
- 延迟关闭
tcp、数据库等连接
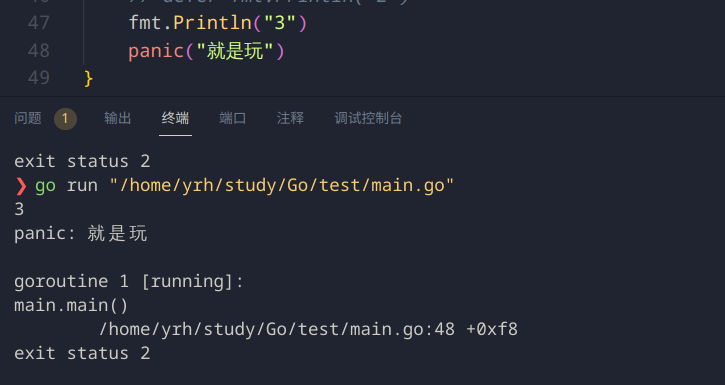
panic
Go语言的类型系统会在编译的时捕捉很多异常,但是有些异常只能在运行时被检查出来,比如数据越界,空指针引用。这些运行异常会引起panic异常。然后在退出之后执行defer语句。
但是我们有时候需要手动宕机
panic("就是玩")
panic recover
我们知道出现panic以后程序会终止,但是如果在程序中遇到不可预料的异常,我们也不应该直接崩溃,我们应该打印、跳过,然后继续运行。
myFuncTest := func(a, b int) (res int) {
defer func() {
if err := recover(); err != nil {
fmt.Println(err)
res = -1
}
}()
res = a / b
return
}
datas := []struct {
a int
b int
}{
{2, 0},
{2, 2},
}
for _, v := range datas {
var res int
if res = myFuncTest(v.a, v.b); res == -1 {
continue
}
fmt.Println(v.a, " / ", v.b, " = ", res)
}
/*
runtime error: integer divide by zero
2 / 2 = 1
*/
range
简介
range 是Go语言相当好用的语法糖,可以在for循环中迭代array slice map channel 字符串等所有涉及遍历的东西。
how to use
切片迭代
nums := []int{1, 2, 3}
for k, v := nums{
//do
}
for k := nums{}
for _, v := nums{}
map迭代,注意map迭代的时候是随机的
mp := make(map[int]int){
1:1
2:2
}
for k, v := range mp{
}
字符串迭代
str := "yrh is sb"
for k, v := range str{
}
channel
ch := make(chan int, 10)
ch <- 1
ch <- 2
close(ch)
for x := range ch {
fmt.Println(x)
}
结构体
tmp := []struct{
int
string
}{
{1, "a"},
{2, "b"},
}
for k, v := range tmp{
}
并发和并行
Go语言的并发特性
Go语言在并发方面提供了语言级的支持,goroutine和chan的相互配合,有了先天的优势。
goroutine是Go协程,概念类似于线程,Go程序运行的时候会自动调度和管理。合理的分配给CPU,让这些协程并发操作。
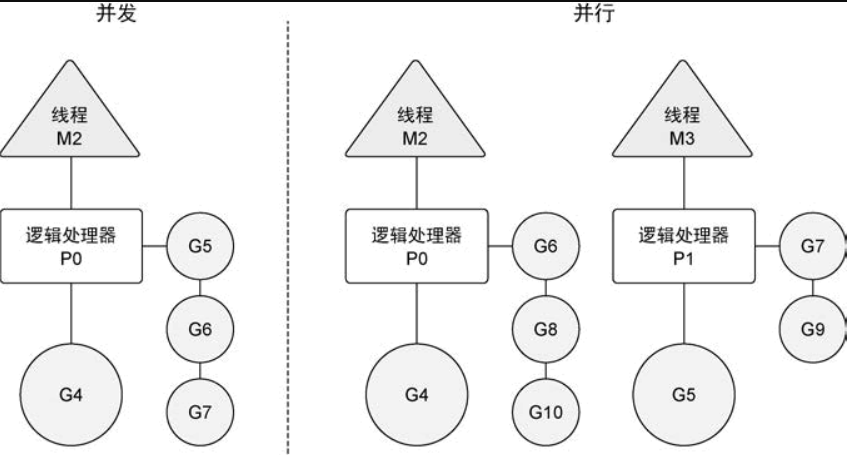
- 并发:把任务在不同的时间点交给处理器进行处理。在同一时间点,任务并不会同时运行。
- 并行:把每一个任务分配给每一个处理器独立完成。在同一时间点,任务一定是同时运行。
很多情况下, 并发的效果比并行好,因为系统可能没有那么多资源。Go语言设计的哲学就是:用较少的资源做更多的事
如果希望让 goroutine 并行,必须使用多于一个逻辑处理器。当有多个逻辑处理器时,调度器会将 goroutine 平等分配到每个逻辑处理器上。这会让 goroutine 在不同的线程上运行。不过要想真的实现并行的效果,用户需要让自己的程序运行在有多个物理处理器的机器上。否则,哪怕 Go语言运行时使用多个线程,goroutine 依然会在同一个物理处理器上并发运行,达不到并行的效果。
- 协程比线程更加轻量级,搭配
channel可以实现高并发 - 线程的栈内存大小一般是
2MB,这个数值可以设置,但是太大了会浪费,太小了不够用。goroutine的栈内存是可变的,初始值是2KB,随着需求可以扩大到1GB - 线程的调度是
OS内核触发的,线程的切换需要CPU寄存器和内存的数据交换。触发方式是CPU时钟,goroutine的调度是自身调度器实现的。
Create & use
创建一个goroutine, 只需要在函数前面加一个go关键字
go func (parma...){}
example:
t := func() {
fmt.Println("Hello")
}
go t()
time.Sleep(time.Second)
-
goroutine和main主进程同时运行。 -
main运行终止会强制销毁所有的协程。
go func(){
fmt.Println("hello")
}()
time.Sleep(time.Second)
和线程不同的是,goroutine没有唯一的id, 所以不能单独管理。
并发等待
简介
goroutine在有时候,函数执行完了,goroutine还没有执行完。
t := func() {
fmt.Println("Hello")
}
go t()
fmt.Println("Over")
/*
Over
*/
使用Sleep等待
t := func() {
fmt.Println("Hello")
}
go t()
time.Sleep(time.Second)
fmt.Println("Over")
/*
Hello
Over
*/
结果是符合预期的,但是我们并不知道要等待多久,所以是不太理想的。
发送信号
done := make(chan bool)
go func() {
for i := 0; i < 10; i++ {
time.Sleep(100 * time.Millisecond)
fmt.Println("hello ", i)
}
done <- true
}()
<-done
fmt.Println("over!")
这种方法不能处理多个协程
WaitGroup
Go语言官方在sync包中提供了WaitGroup类型可以解决这个问题,其文档描述总结如下:

t := func(_wg *sync.WaitGroup) {
defer _wg.Done()
for i := 0; i < 10; i++ {
fmt.Println("hello!", i)
}
}
var wg sync.WaitGroup
wg.Add(2)
go t(&wg)
go t(&wg)
fmt.Println("Over")
wg.Wait()
/*
Over
hello! 0
hello! 1
hello! 2
hello! 3
hello! 4
hello! 5
hello! 6
hello! 7
hello! 8
hello! 9
hello! 0
hello! 1
hello! 2
hello! 3
hello! 4
hello! 5
hello! 6
hello! 7
hello! 8
hello! 9
*/
因为goroutine是并发的,所以输出顺序是混乱的。
bug
参考闭包的bug
channel
简介
前面说了Go语言是语言级别支持并发的
它有一个设计哲学很特别 不要通过共享内存来通信,而应通过通信来共享内存
传统语言中,是使用全局变量来进行数据共享的。Go会在协程和协程之间打通一个通道。

channel是goroutine之间通讯的东西,用来发送消息和接收消息。
声明和初始化
channel是类型相关的,也就是一个channel只能传递一种类型的值
channel一般声明
var myChannel chan type
与普通变量声明不同的是,在类型前面加了chan关键字,type则指定了这个channel能传递的元素类型。
前面提到过,通道是一个引用类型,初始值是nil,对于值为nil的通道,无论具体是什么类型,他所属的操作都会处于堵塞状态。
必须手动make初始化
a := make(chan int)
b := make(chan float64)
显而易见,通道是一个队列,既然是队列那么就会有大小,如果没有声明具体的大小,就会被认为是无缓冲的,也就是必须有goroutine接受,不然就会堵塞。
a := make(chan int, 100)
use
下面有一个无缓冲的例子
func noCacheDemo() {
a := make(chan int)
a <- 1
z := <-a
fmt.Println(z)
}
- 我们在第三行给
channel写入了数据,在第四行读出数据 - 没有使用
go关键词,说明在同一个协程中
上面提到,channel是给不同的goroutine通信的,所以不能在同一个协程内通信。会死锁。
原因就是没有其他协程来接受数据,隧道无缓冲,所以永远堵塞在发送方。
要解决这个问题,只需要放到不同的goroutine
func noCacheDemo() {
a := make(chan int)
go func() {
a <- 1
}()
z := <-a
fmt.Println(z)
}
func standerDemo() {
ch := make(chan int)
go func() {
defer close(ch)
for i := 0; i < 10; i++ {
ch <- i
}
}()
for v := range ch {
fmt.Println(v)
}
}
/*
0
1
2
3
4
5
6
7
8
9
*/
-
range chan可以不断接受数据,直到通道关闭,假如通道不关闭则会永远堵塞,无法编译。 - 必须在发送端关闭通道,因为不知道接收端什么时候能接受完数据,如果向已经关闭的通道发送数据会
panic - 使用
defer关闭通道,防止程序异常时未正常关闭。
channel的关闭
请使用defer修饰去关闭
defer close(ch)
- 同一个通道只能关闭一次,重复关闭会
panic
Demo
func main(){
chanInt := make(chan int, 10)
done := make(chan struct{})
defer close(done)
go func() {
var wg sync.WaitGroup
defer close(chanInt)
for i := 0; i < 10; i++ {
wg.Add(1)
go Send(chanInt, &wg)
}
wg.Wait()
}()
go func() {
var wg sync.WaitGroup
for i := 0; i < 5; i++ {
wg.Add(1)
go Received(chanInt, &wg)
}
wg.Wait()
done <- struct{}{}
}()
<-done
}
func Send(c chan int, wg *sync.WaitGroup) {
c <- rand.Int()
wg.Done()
}
func Received(c chan int, wg *sync.WaitGroup) {
for v := range c {
fmt.Println("received: ", v)
}
wg.Done()
}
deadlock
常用补充
Sort
简介
import "sort"
对于常用的数据类型, sort 包提供了对[]int []float64 []string 切片的排序支持。
func Ints(x []int)
func Float64s(x []float64)
func Strings(x []string)
自定义比较器
使用sort.Slice()函数可以排序任意类型的切片,但是需要用户提供函数来判断元素的大小,函数类型为func(i, j int) bool, 与C++不同的是 ,参数i,j 是序列中索引。
func Slice(x interface{}, less func(i, j int) bool )
如果想要稳定排序的话,使用sort.SliceStable(),在排序切片的时候会保留相等元素的初始顺序。
Example:
func main(){
student := []struct{
Name string
Age int
agA int
}{
{"yrh", 22, 20},
{"yrh1", 21, 21},
{"yrh2", 20, 22},
}
sort.SliceStable(student, func(i, j int) bool{
return student[i].Age < student[j].Age
})
fmt.Println(student); // [{yrh2 20 22} {yrh1 21 21} {yrh 22 20}]
}
排序任意数据结构
使用sort.Sort()|sort.Stable() 可以对任意数据结构进行排序
一个内置的排序算法需要知道三个东西:序列的长度,表示两个元素比较的结果,一种交换两个元素的方法, sort.Interface 也是这么实现的
type Interface interface{
Len() int
Less(i, j int) bool
Swap(i, j int)
}
相对于前两种排序,用起来麻烦,但是显而易见的更加普遍使用。
type Student struct {
Name string
Age int
egA int
}
type ByStudent []Student
func (a ByStudent) Len() int { return len(a) }
func (a ByStudent) Less(i, j int) bool {
if a[i].Age > a[j].Age {
return false
}
return a[i].egA < a[j].egA
}
func (a ByStudent) Swap(i, j int) {
a[i], a[j] = a[j], a[i]
}
func main() {
student := []Student{
{"yrh", 22, 20},
{"yrh1", 21, 21},
{"yrh2", 20, 22},
}
sort.Stable(ByStudent(student))
fmt.Println(student) // [{yrh 22 20} {yrh1 21 21} {yrh2 20 22}]
}
语法糖(待补充......)
可变长参数
Go语言允许一个函数把任意数量的值作为参数,Go语言内置了...操作符,但是得在函数的最后一个形参才可以使用,他必须遵循以下注意事项:
- 可变长参数必须在函数列表的最后一个
- 把可变长参数当切片来解析,可变长参数没有值时就是
nil切片 - 可变长参数类型必须一致
func test(a int, b ...int){
return
}
我们在函数传参的时候可以使用...解包作为参数列表,append就是一个例子
sl := []int
sl = append(s1, 1)
sl = append(s1, ...s1)
append方法定义如下:
func append(slice []Type, elems ...Type) []Type
声明不定长数组
数组是有固定长度的,我们再声明数组的时候一定要声明长度,但是懒得写的时候,可以用...操作符声明数组长度,剩下的交给编译器
a := [...]int{1, 3, 5}
//等价于
a := [3]int{1, 3, 5}
有时候我们需要声明一个大数组,但是特定的下标需要单独设定,可以这样
a := [...]int{1:20, 999:10} // 除了a[1] a[999]其他都是0
init函数
Go语言提供了优先级高于main函数执行的init函数,初始化后每个包会自动执行init函数,每个包可以有多个init函数,每个包的源文件也可以有多个init函数,加载顺序如下:
从当前包开始,如果当前包包含多个依赖包,则先初始化依赖包,层层递归初始化各个包,在每一个包中,按照源文件的字典序从前往后执行,每一个源文件中,优先初始化常量、变量,最后初始化init函数,当出现多个init函数时,则按照顺序从前往后依次执行,每一个包完成加载后,递归返回,最后在初始化当前包!
init函数实现了sync.Once,无论包被导入多少次,init函数都只执行一次。
忽略导包
Go语言在设计师有代码洁癖,在设计上尽可能避免代码滥用,所以Go语言的导包必须要使用,如果导包了但是没有使用的话就会产生编译错误,但有些场景我们会遇到只想导包,但是不使用的情况,比如上文提到的init函数,我们只想初始化包里的init函数,但是不会使用包内的任何方法,这时就可以使用 _ 操作符号重命名导入一个不使用的包:
import _ "github.com/asong"
忽略字段
在开发中,有些方法可能会复用,但是这个方法的返回值我们不一定需要,可以使用 _操作符,将不需要的值复制给_
_, ok := test(a,b)
Json序列化忽略某些字段
大多数时候我们会用到struct 做序列化操作,但是有时候不需要json的某些字段参与序列化,-操作符可以帮助处理,Go语言的结构体提供标签功能,在结构体标签中使用-操作符可以对不需要序列化的字段做特殊处理
type Person struct{
name string `json:"-"`
age int `json:"age"`
}
Json序列化忽略控制字段
在使用json.Marshal()进行序列化操作的时候不会忽略struct里面的空值, 默认输出字段的零值,假如想在序列化的时候忽略这些空值字段,可以使用omitemptt 标签
type myTest struct {
Name string `json:"name"`
Age int `json:"age"`
Email string `json:"email,omitempty"`
}
func test() {
hh := myTest{
Name: "yrh",
Age: 20,
Email: "1@myyrh.com",
}
hh2 := myTest{
Name: "yrh",
}
b, err := json.Marshal(hh)
if err != nil {
}
b2, err := json.Marshal(hh2)
if err != nil {
}
fmt.Printf("%s\n%s\n", b, b2)
}
/*
{"name":"yrh","age":20,"email":"1@myyrh.com"}
{"name":"yrh","age":0}
*/
短变量声明
类似
a := 10
- 短变量声明只能在函数内使用,不能用于初始化全局变量
- 短变量声明代表引入一个新的变量,不能在同一作用域重复声明变量
- 多变量声明中如果其中一个变量是新变量,那么可以使用短变量声明,否则不可重复声明变量
类型断言
我们通常会使用interface, 一种是带方法的interface, 一种是空的interface 我们可以用interface{}来当做泛型使用,当空的interface{}入参或者返回值的时候,我们就用到类型断言,
value, ok := x.(T)
value := x.(T)
x是interface类型,T是具体的类型,方式一是安全的断言,方式二断言失败会触发panic
- 如果x是空接口类型:
- 空接口类型断言实质是将
eface中_type与要匹配的类型进行对比,匹配成功在内存中组装返回值,匹配失败直接清空寄存器,返回默认值。
- 空接口类型断言实质是将
- 如果x是非空接口类型:
- 非空接口类型断言的实质是
iface中*itab的对比。*itab匹配成功会在内存中组装返回值。匹配失败直接清空寄存器,返回默认值。
- 非空接口类型断言的实质是
切片循环
//遍历不关心数据,适用于切片、数组、字符串、map、channel
for range T{}
///遍历获取索引或数组,切片,数组、字符串就是索引,map就是key,channel就是数据
for key := range T{}
// 遍历获取索引和数据,适用于切片、数组、字符串,第一个参数就是索引,第二个参数就是对应的元素值,map 第一个参数就是key,第二个参数就是对应的值
for key, value := range T{}
select控制结构
Go语言提供了select关键词,select配合channel能够让Goroutine同时等待多个channel读写,在channel状态未改变之前,select会一直堵塞当前线程或者Goroutine
func fib(ch chan int, done chan struct{}) {
x, y := 0, 1
for {
select {
case ch <- x:
x, y = y, x+y
case <-done:
fmt.Println("Over")
return
}
}
}
func selectTest() {
ch := make(chan int)
done := make(chan struct{})
go func() {
for i := 0; i <= 10; i++ {
fmt.Println(<-ch)
}
done <- struct{}{}
}()
fib(ch, done)
}
select与switch具有相似的控制结构,与switch不同的是,select中的case中的表达式必须是channel的收发操作,当select中的两个case同时被触发时,会随机执行其中的一个。为什么是随机执行的呢?随机的引入就是为了避免饥饿问题的发生,如果我们每次都是按照顺序依次执行的,若两个case一直都是满足条件的,那么后面的case永远都不会执行。
