
本文实现了mit6.824的lab1,需要提前阅读论文MapReduce
先来一张成功的截图
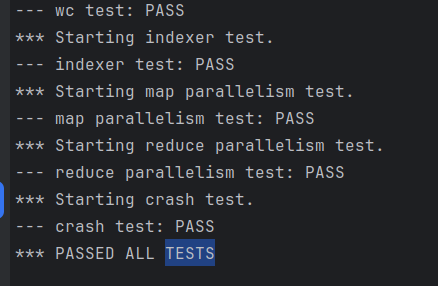
说明:基于本人的poor english 我选择阅读翻译版本的论文。
MapReduce框架
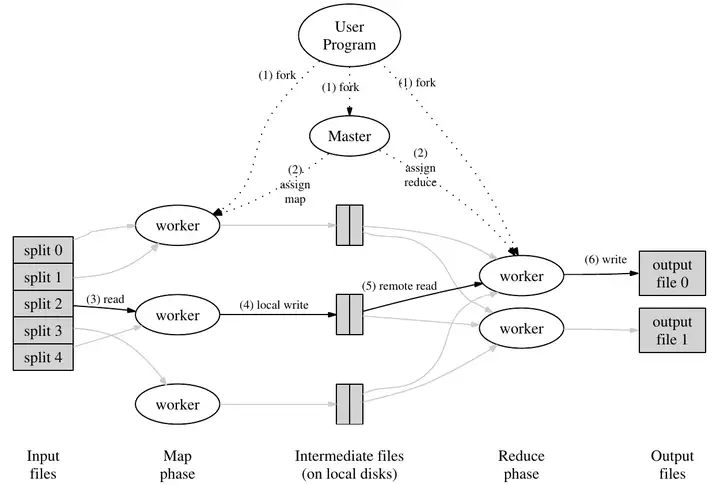
论文中对于MapReduce 主要分成四个角色:
-
User Program: 客户端,用来协调MapReduce任务。 -
Master: 用于分配任务、协调任务的进行。 -
Map Worker: 执行Map方法的进程。 -
Reduce Worker: 执行Reduer方法的进程。
输入数据以文件形式存储在系统中(在下一节讲到了)。在Master 进程的调整分配下运行map任务,生成了一些中间体,这些中间体是以k-v键值对形式存在的。另外一些进程运行了Reduer任务,产生最终输出。
-
Job: 整个MapReduce计算称为Job。 -
Task: 每一次MapReduce调用称为Task。
Map函数
Map函数使用一个key和一个value作为参数。
普遍上,key是输入文件的名字,我们一般不关心他,value是输入文件的内容。
对于一个单词计数器来说,value包含了要统计的文本,我们先把这些文本拆分单词,对于每一个单词,我们都调用一个emit。这个emit由MapReduce框架提供,并且这里的emit是属于Map的。emit接收两个参数,其中一个是key,一个是value。比如在单词计数器里面,就是调emit("apple","1")。在一个单词MapReduce Job中,这就是Map函数的实现。Map函数实际上不需要知道任何分布式相关的信息,不需要知道有多少台设备,不需要知道会通过网络来传输数据。
Reduce函数
Reduce函数的入参是某个特定的key的所有实例。所以接受的参数也是key和value。其中value是一个数组,里面的每一个元素都是Map函数输出的key作为实例的value。对于单词计数器来说,key就是一个单词,value是一串数组。在Reduce函数中,也有自己的emit函数,这里的emit函数只接受一个value参数,这个value会作为Reduce函数入参的key的最终输出。
What's More
- 实际上,对于复杂的阶段分析和迭代算法,比如评估网页的重要性,我们可能会把
Reduce的输出在丢到Map里面继续迭代
Lab1
Lab1要求我们实现一个和Mapreduce类似机制的单词统计器。
输入文件在src/main中,文件名是pg-*.txt,要统计他们出现的单词和出现的次数。
首先观察文件结构
.
├── go.mod
├── Makefile
└── src
├── kvraft
│ ├── client.go
│ ├── common.go
│ ├── config.go
│ ├── server.go
│ └── test_test.go
├── labgob
│ ├── labgob.go
│ └── test_test.go
├── labrpc
│ ├── labrpc.go
│ └── test_test.go
├── main
│ ├── diskvd.go
│ ├── lockc.go
│ ├── lockd.go
│ ├── mrmaster.go
│ ├── mr-out-0
│ ├── mrsequential.go
│ ├── mrworker.go
│ ├── pbc.go
│ ├── pbd.go
│ ├── pg-being_ernest.txt
│ ├── pg-dorian_gray.txt
│ ├── pg-frankenstein.txt
│ ├── pg-grimm.txt
│ ├── pg-huckleberry_finn.txt
│ ├── pg-metamorphosis.txt
│ ├── pg-sherlock_holmes.txt
│ ├── pg-tom_sawyer.txt
│ ├── pkg
│ │ └── mod
│ │ └── cache
│ │ └── lock
│ ├── test-mr.sh
│ ├── viewd.go
│ └── wc.so
├── models
│ └── kv.go
├── mr
│ ├── master.go
│ ├── rpc.go
│ └── worker.go
├── mrapps
│ ├── crash.go
│ ├── indexer.go
│ ├── mtiming.go
│ ├── nocrash.go
│ ├── rtiming.go
│ └── wc.go
├── porcupine
│ ├── bitset.go
│ ├── checker.go
│ ├── model.go
│ ├── porcupine.go
│ └── visualization.go
├── raft
│ ├── config.go
│ ├── persister.go
│ ├── raft.go
│ ├── test_test.go
│ └── util.go
├── shardkv
│ ├── client.go
│ ├── common.go
│ ├── config.go
│ ├── server.go
│ └── test_test.go
└── shardmaster
├── client.go
├── common.go
├── config.go
├── server.go
└── test_test.go
-
mrmaster.go:用来启动master进程,启动后调用mr/master -
mrworker.go:用来启动worker进程,启动后调用mr/worker -
mrapps:是我们实际上要执行的任务,具体的map和reduce任务。 -
mr:实现lab1的文件夹:-
master.go:作为master节点所具备的功能 -
worker.go:作为worker节点所具备的功能 -
rpc.go:实现master和worker远程调用的数据结构
-
之前的版本没法处理crash-test 重新构建一个。现在有大概率失败,不知道为啥
程序的大概流程是这样的,我拿drawio摸一个
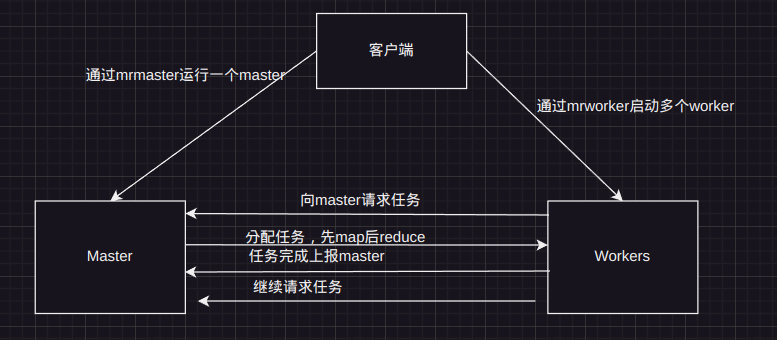
结构分析
rpc
type RequestTaskReply struct {
Task *Task
NReduce int
DoneStatus bool
}
type ReportTaskResponse struct {
WorkType int // 0 map 1 reduce
WorkId int
WorkFiles []string
}
type DoneTaskReply struct {
X int
}
type TaskArgs struct{}
const (
MapTask = 0
ReduceTask = 1
Maping = 0
Reduceing = 1
Ready = 0
Running = 1
Finished = 2
)
master
对于一个master 他需要有自己的结构
type Master struct {
MapQue []*Task // Map任务队列 未完成的
ReduceQue []*Task // Reduce任务队列 未完成的
Files []string // 要处理的文件
MapCount int // Map任务 现在看来是没用了,因为本来是我给MapQue写的是channel后来改成了切片
ReduceCount int // Reduce任务数量 用于work生成temp文件
Whiching int // 正在进行什么任务,map or reduce
Lock sync.Mutex // 锁
WorkID int // id
IsDone bool // 是否完成
}
task的结构
type Task struct {
TaskType int // Task的类型 map or reduce
MapId int // map任务的id
ReduceId int // reduce任务id
TaskStatus int // 状态 finished running ready
InputFile string // 操作的文件
BeginTime time.Time // 开始时间,用于处理crash
}
对于处理map任务和reduce任务的时候我是这样的:
- 一个
worker刚开始的时候,肯定是处理map任务的,所以在创建work的时候就把map任务生成,
m.Lock.Lock()
for _, file := range files {
task := Task{
TaskType: MapTask,
InputFile: file,
TaskStatus: Ready,
MapId: 0,
}
m.MapQue = append(m.MapQue, &task)
}
- 当处理完
map任务,就直接把reduce任务生成,供后续去获取任务
if flag := func() bool {
m.Lock.Lock()
for i := 0; i < len(m.MapQue); i++ {
task := m.MapQue[i]
if task.TaskStatus != Finished {
m.Lock.Unlock()
return false
}
}
m.Lock.Unlock()
return true
}(); flag {
m.Whiching = Reduceing
m.Lock.Lock()
for i := 0; i < m.ReduceCount; i++ {
task := Task{
TaskType: ReduceTask,
InputFile: fmt.Sprintf("/var/tmp/mr-*-%v", i),
TaskStatus: Ready,
ReduceId: 0,
}
m.ReduceQue = append(m.ReduceQue, &task)
}
m.Lock.Unlock()
}
对于work获取任务的时候,肯定是先判断正在处理什么,简易的代码
func (m *Master) GetTask(args *TaskArgs, reply *RequestTaskReply) error{
if m.Done(){
reply.DoneStatus = true
return nil
}
if m.Whiching == Maping{
for _, task := range m.MapQue{
if task.TaskStatus == Ready{
// 分发
return nil
}
}
// 根据上面的 判断是否完成map任务并生成reduce任务
}else{
for _, task := range m.ReduceQue{
if task.TaskStatus == Ready{
// 分发
return nil
}
}
flag := func(){}() // 判断reduce是否都完成
if flag{ // 所有任务都已经完成
reply.DoneStatus = true
time.Sleep(time.Second * 2)
m.Lock.Lock()
m.IsDone = true
m.Lock.Unlock()
}
}
}
work完成任务肯定是要上报的
func (m *Master) ReportWorkDone(args *ReportTaskResponse, reply *DoneTaskReply) error{
if args.WorkType == MapTask{
for task := range m.MapQue{
// 先判断任务是否超时
if task.MapId == mapWorkId && task.TaskStatus == Running{
//把temp文件移到工作目录
task.TaskStatus = Finished
for _, file := range args.WorkFiles {
src, err := os.Open(file)
defer src.Close()
if err != nil {
log.Fatal( err)
}
DIR, _ := os.Getwd()
filename := filepath.Base(file)
f := DIR + "/" + filename
dst, err := os.Create(f)
defer dst.Close()
if err != nil {
log.Fatal(err)
}
_, err = io.Copy(dst, src)
if err != nil {
log.Fatal(err)
}
}
break
}
}
}else{
// 同上
}
}
对于处理crash任务,我的想法是开一个协程,定时扫描正在进行的任务类型的所有任务,如果超时10s以上,那么直接把任务状态设置为Ready等待分发即可,但是就是因为这个crash-test,我写了两个版本,第二个版本有时候可以pass,
crash.go
func maybeCrash() {
max := big.NewInt(1000)
rr, _ := crand.Int(crand.Reader, max)
if rr.Int64() < 330 {
// crash!
os.Exit(1)
} else if rr.Int64() < 660 {
// delay for a while.
maxms := big.NewInt(10 * 1000)
ms, _ := crand.Int(crand.Reader, maxms)
time.Sleep(time.Duration(ms.Int64()) * time.Millisecond)
}
}
可以看出,有 1/3几率直接退出,1/3几率等到0-10s,1/3几率直接开始。
我的想法是,开一个协程,每两秒扫一下running的任务,如果超时了,就把状态设置Ready
func (m *Master) HeartBeatForTimeOut() { // 非心跳机制
for !m.Done() {
time.Sleep(2 * time.Second)
m.Lock.Lock()
if m.Whiching == Maping {
for _, task := range m.MapQue {
if task.TaskStatus == Running && (time.Since(task.BeginTime) > time.Duration(10*time.Second)) {
task.TaskStatus = Ready
}
}
} else {
for _, task := range m.ReduceQue {
if task.TaskStatus == Running && (time.Since(task.BeginTime) > time.Duration(10*time.Second)) {
task.TaskStatus = Ready
}
}
}
m.Lock.Unlock()
}
}
work
work结构
type OneWorker struct {
WorkerID int // 工作 id
Mapf func(string, string) []KeyValue // 程序提供的Mapf
Reducef func(string, []string) string // 程序提供的Reducef
Task *Task // 执行的任务
NReduce int // educe任务的数量
IsDone bool // 是否完成
}
初始化的时候,直接for {}
func Worker(mapf func(string, string) []KeyValue, reducef func(string, []string) string) {
worker := OneWorker{
WorkerID: -1,
Mapf: mapf,
Reducef: reducef,
IsDone: false,
}
for !worker.IsDone {
worker.work()
}
}
对于一个work工作,在流程就是 获取任务 -> 处理任务 -> 上报结果 -> 获取任务 ....
所以在work()里面就按照这个流程去工作
func (work *OneWorker) work() {
task := work.RequireTask() // 获取任务
if task != nil {
work.Task = task
if task.TaskType == MapTask {
work.WorkerID = task.MapId
intermediate := work.generateMapResult(task) // 调用mapf生成结果
file := work.writeMapTempFiles(intermediate) // 写到文件里面
work.TaskDone(file, MapTask) // 上报
} else {
work.WorkerID = task.ReduceId
intermediate := work.generatorReduceResult(task.InputFile) // 调用reducef
files := work.writeReduceTempFiles(task, intermediate) // 写到文件
work.TaskDone(files, ReduceTask) // 上报
}
}
}
获取任务
func (work *OneWorker) RequireTask() *Task {
args := TaskArgs{}
reply := RequestTaskReply{}
call("Master.GetTask", &args, &reply)
if &reply != nil {
if reply.DoneStatus { // 如果任务都完成了
work.IsDone = true // 当前任务不需要处理
return nil
}
work.NReduce = reply.NReduce
return reply.Task
} else {
return nil
}
}
调用mapf/reducef生成结果
func (work *OneWorker) generateMapResult(task *Task) []KeyValue {
NowIntermediate := make([]KeyValue, 0) // 中间文件
file, err := os.Open(task.InputFile)
if err != nil {
log.Fatal(err)
}
content, err := ioutil.ReadAll(file)
if err != nil {
log.Fatal(err)
}
file.Close()
kva := work.Mapf(task.InputFile, string(content))
NowIntermediate = append(NowIntermediate, kva...)
return NowIntermediate
}
func (work *OneWorker) generatorReduceResult(task *Task) []KeyValue {
intermedia := make([]KeyValue, 0)
files, err := filepath.Glob(task.InputFile)
if err != nil {
log.Fatal(err)
}
for _, filepath := range files {
file, err := os.Open(filepath)
if err != nil {
log.Fatal(err)
}
dec := json.NewDecoder(file)
for {
var kv KeyValue
if err := dec.Decode(&kv); err != nil {
break
}
intermedia = append(intermedia, kv)
}
}
// mrsequential
sort.Sort(ByKey(intermedia))
res := make([]KeyValue, 0)
i := 0
for i < len(intermedia) {
j := i + 1
for j < len(intermedia) && intermedia[j].Key == intermedia[i].Key {
j++
}
values := make([]string, 0)
for k := i; k < j; k++ {
values = append(values, intermedia[k].Value)
}
//defer work.CrashRecover()
output := work.Reducef(intermedia[i].Key, values)
kv := KeyValue{Key: intermedia[i].Key, Value: output}
res = append(res, kv)
i = j
}
return res
}
生成文件的时候,按照提示:
- map任务
- 先利用ioutil.TempFile生成临时文件,等
Json处理完,在Rename成mr-X-Y格式的文件
- 先利用ioutil.TempFile生成临时文件,等
- Reduce任务同上
任务上报 直接报就行
func (work *OneWorker) TaskDone(files []string, Type int) {
args := ReportTaskResponse{
WorkType: Type,
WorkId: work.WorkerID,
WorkFiles: files,
}
reply := DoneTaskReply{}
call("Master.ReportWorkDone", &args, &reply)
}
差不多就这些了
