

最近看教程和groupcache,糊了一个非RPC通信的分布式缓存,简单总结一下。
分布式缓存
缓存非常常见,比如网站的CDN缓存,Redis集群等。
对于类似map的k-v 缓存策略,大概有几个问题
- 内存不够?
- 对于这个问题,我们可以采取一个策略,对于被策略淘汰的键值,我们在新增键值的时候替换掉即可。
- 性能不够?

- 这个可以通过多机分布式来实现,但是我写的没有实现多机,只实现了多进程。
- 负载均衡?
- 我只实现了一致性哈希,应该还需要一个
master来调控,我没写....`
- 我只实现了一致性哈希,应该还需要一个
- 缓存击穿?
- 实现思路大概就是,对于多次相同的请求,给一个缓冲,实现只处理一次请求,然后多次返回这个返回值。
- DO or TODO
- LRU
- 单机并发、分布式节点
- 防止缓存击穿
- PRC
实现
LRU淘汰策略
LRU 顾名思义 Least Recently Used , 最近最少使用,相对于LFR和FIFO来说,应该是最适合的。
我们维护一个队列,对于使用过的,就放到队列最前面,显而易见,淘汰的时候只需要把队尾删掉即可。
数据结构
-
map: 用来存储缓存的键值 - 双向链表: 把所有的key映射到上面,这样的操作都是
O(1)的
type Value interface { // Value 范型
Len() int
}
type Entry struct { // 双向链表上面的
key string
value Value
}
type Cache struct {
maxBytes int64 // 最大的容量
nBytes int64 // 当前已经使用的
List *list.List // 双向链表
cache map[string]*list.Element // 映射的数据
handleRemove func(key string, value Value) // 自定义remove 类似于 删掉之后的后续操作
}
//new操作
func New(maxBytes int64, handleRemove func(string, Value)) *Cache {
return &Cache{
maxBytes: maxBytes,
List: list.New(),
cache: make(map[string]*list.Element),
handleRemove: handleRemove,
}
}
查找
查找操作就是,直接在list上面查找,找到之后就把*list.element移动到维护的队头。
func (c *Cache) Get(key string) (Value, bool) {
if value, ok := c.cache[key]; ok {
c.List.MoveToFront(value)
kv := value.Value.(*Entry) // 断言
return kv.value, true
}
return nil, false
}
删除
删除操作就是,查找队尾,如果不为空就remove,然后更新一下信息。
func (c *Cache) Delete() {
ele := c.List.Back()
if ele != nil {
c.List.Remove(ele)
kv := ele.Value.(*Entry)
delete(c.cache, kv.key)
c.nBytes -= int64(len(kv.key)) + int64(kv.value.Len())
if c.handleRemove != nil {
c.handleRemove(kv.key, kv.value)
}
}
}
添加
添加的时候,基本思路就是,如果存在,就更新value,如果不存在就扔到对头,然后执行淘汰。
func (c *Cache) Add(key string, value Value) {
if ele, ok := c.cache[key]; ok {
c.List.MoveToFront(ele)
kv := ele.Value.(*Entry)
c.nBytes += int64(len(kv.key)) + int64(kv.value.Len())
kv.value = value
} else {
ele := c.List.PushFront(&Entry{key, value})
c.cache[key] = ele
c.nBytes += int64(len(key)) + int64(value.Len())
}
for c.maxBytes != 0 && c.maxBytes < c.nBytes {
c.Delete()
}
}
一致性哈希
为什么要使用一致性哈希?
我们考虑这么一个问题,在分布式缓存中,当一个节点接收到一个请求,但是该节点并没有存储缓存值,那么他要面临:从谁那里获取数据。 我们假设一共有五个节点。
- 随机选择节点: 每次将会有$\frac{1}{5}$ 的概率, 效率很低
- 自定义哈希: 我们对于每一个
key,利用某种算法,转成整数,然后 $% (sum(serve))$ 得到一个分布式节点的id,但是这种算法有个明显的缺陷是,假如有节点下线了,那么所有缓存都会失效
算法原理
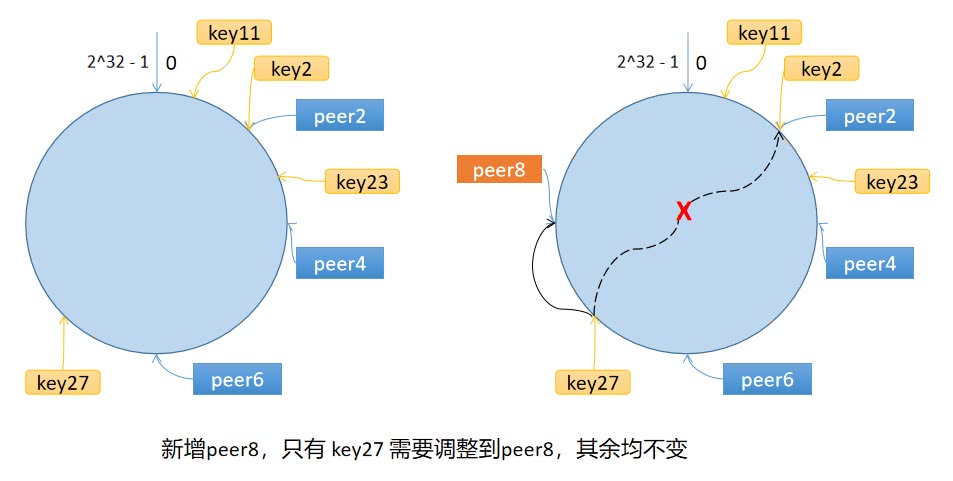
步骤
一致性哈希维护一个环,他把key映射到$2^{32}$大小的环上
- 计算 节点 的哈希值,放到环上
- 计算
key的哈希值,放到环上,顺时针找到的第一个节点,就是应该选取的节点。
数据倾斜
假如系统节点太少,很容易导致key的倾斜。例如上面例子中的 peer2,peer4,peer6 分布在环的上半部分,下半部分是空的。那么映射到环下半部分的 key 都会被分配给 peer2,key 过度向 peer2 倾斜,缓存节点间负载不均。
应对这个问题,引出了虚拟节点的概念,一个真实节点对应多个虚拟节点。
type Hash func(data []byte) uint32
type Map struct {
hash Hash // 自定义哈希算法
replicas int //虚拟节点倍数
keys []int // 哈希环
hasMap map[int]string // 虚拟节点和真实节点
}
func NewHash(replicas int, has Hash) *Map {
m := &Map{
hash: has,
replicas: replicas,
keys: make([]int, 0),
hasMap: make(map[int]string),
}
if m.hash == nil {
m.hash = crc32.ChecksumIEEE
}
return m
}
添加节点
func (m *Map) Add(keys ...string) {
for _, key := range keys {
for i := 0; i < m.replicas; i++ {
hash := int(m.hash([]byte(strconv.Itoa(i) + key)))
m.keys = append(m.keys, hash)
m.hasMap[hash] = key
}
}
sort.Ints(m.keys)
}
获取节点
func (m *Map) Get(key string) string {
if len(m.keys) == 0 {
return ""
}
hash := int(m.hash([]byte(key)))
idx := sort.Search(len(m.keys), func(i int) bool {
return m.keys[i] >= hash
})
return m.hasMap[m.keys[idx%len(m.keys)]]
}
